How fun is it to be the first one who comes up with the solution! Such a great feeling knowing that you were the one who solved the problem. However, it’s easy to haste and provide a solution to the symptom and not the actual problem. I guess we all do that from time to time.
Most of the times the actual problem hides behind the symptom, and when we focus on providing a fix for the symptom, not only that we might miss the problem (and not fix it at all), we could increase the severity of the problem or hide it even further.
Here are some tips that help me (every day) come up with solutions for the actual problem and not for the symptom:
Try to describe and characterize the problem and not the symptom. Ask yourselves what could cause the symptom (the problem) that you see. Try listing all possible sources you can come up with. Focus on gathering information and describing the issue at hand.
Focus on the “Story”. Ignore the visible issue and focus on the “story”. The story should tell the the full (end-to-end) process that is currently not working. A good evidence that you got the story right is your ability to tell the story to someone else and make them understand it.
Start by assuming you don’t know. When you assume that you don’t know it forces you to investigate more thoroughly and to make sure you understand what you find.
Ask yourselves why. Why a certain outcome came to be? Why ‘X’ happened? What could have caused ‘X’ to occure?
Zoom-Out. After gathering some information try to zoom-out and arrange all the facts that you have into the Story mentioned in section (2). Make sure it is short and clear. This way, if you need assistance, and have to get someone new to speed on this, it will be easy and clear.
Don’t be afraid to ask questions. If you have questions, find the relevant person and go ask the question regardless to how sophisticated (or not) you think your question is. Even if you think or feel that your question is stupid. There is no such thing as a stupid question when you are trying to investigate an issue. You can always throw the word “Production” in. It will definitely help 😁.
Avoid theological and theoretical discussions. Do your best to avoid theoretical discussions around how that process or flow should work, and what should be the best-practice for it. As important as these discussion are, they are irrelevant at that point of time and will only waste your precious time. However, you should make sure these discussions are held right after the issue is resolved.
Verify and validate your suspicions and conclusions before you implement them. Do not settle for thinking only. Make an effort to validate and verify that your suspicions are correct and evident.
Focus on the facts and data that you see. Do not forget to use all the data and facts that you see when constructing your solution. No data or fact should be ignored, as ignoring them might shift you away from the required solution.
I come across this question quite often. Most of those who ask this question are after the same thing — quick automation with no development and/or maintenance overhead. Don’t we all crave an effortless piece of software with no bugs and maintenance? Yeh well, eventually we all realize that this is a dream we don’t really want to pursue as it will probably result in a dysfunctional piece of software.
So what are the perceived benefits of recording automated tests rather than developing them?
No need for developers – automated test development could be done by anyone and doesn’t require development skills
No false-negative results – recording the test holds less room for errors, thus providing a lesser chance for failures that are not application bugs (automation issues).
No maintenance is needed – when recording automated tests, the code is generated automatically and hardly requires maintenance
No complicated object-model and constant adjustments – the code is automatically generated when recording automated tests, thus no need for an object-model or hardly any code adjustments.
Easy to use and quick to develop – recording an automated test is super quick, you just hit the record button, do whatever you want to be included in your test, and then hit the stop button. A piece of cake.
Real benefit or only a perceived one?
Let’s examine these perceived benefits and see if there are any real and actual benefits there.
1 – No need for developers?
Using unskilled personnel for developing automated tests is always a bad decision. The point is simple, you need a software engineer for developing code. Thus, by doing so, we are actively using non-professional employees for an important task that might affect the quality of our product.
For example, let’s say we’re using .NET and decided to use Microsoft’s Coded-UI recording capabilities (I must point out that they do a very good job detecting elements on screen). The basis for test recording is to “read” user actions and translate them into re-runnable code. In order to do so, Microsoft Coded-UI generates the code inside a map file. one file (default) with all generated code from all recordings. Now think about 100 recorded tests… The result is hundreds if not thousands of generated code lines (!) What happens if something changes in your product? How will those tests be adjusted? Who will be able to go through all the generated code and change it? This approach is bound to fail as it is 100% unmaintainable and is even more dangerous when assigning such a task to an employee with an incompatible skill set.
Well-written automation includes a solid object model which is constantly updated and evolves alongside the product it is intended to test. Moreover, such automation must comply with common code development conventions and patterns to make it as generic and maintainable as possible.
2 – No False-Negative Results?
The common claim will be that recording a test holds less room for errors and thus is less likely to have failures that are not application bugs (automation issues). This is completely wrong.
Every piece of software has bugs, and most of the time, automation test issues occur as a result of changes in the Application Under Test (AUT), which actually requires the code to be adjusted rather than fixed…
False-negative results are a natural part of automated tests since the AUT is constantly evolving and changing, which requires adjustments to the automatic tests, and the automatic tests are a piece of software and as such, they might have bugs.
The real question here is, what is the best way to handle those false-negative results.
This is a mistake at best. No piece of software requires zero maintenance and we’re discussing an automatically-generated piece of software… Maintenance will always be required and should be treated as such. Don’t forget that this piece of software depends on another piece of software (your AUT) which is constantly changing.
4 – No complicated object-model and constant adjustments?
A complicated object-model is always better than not having an object-model at all. However, as with every piece of software, the object-model for your automated tests should be carefully designed and should be constantly reviewed and adjusted according to the requirements and needs. And regarding the adjustments, they will always be there, and they should as the AUT is constantly evolving.
Finally, something we can consider as true (or real). Recording tests is amazingly easy to use and quick to develop. No doubt about it. However, when considering all the downsides, is it really easy to use and quick to develop? I don’t think so…
So What Should It Be Used For?
As you may have figured out by now, I think that the recording strategy is not only inefficient but also dangerous. However, it might be quite useful when used for the following:
Iterative simple test (that doesn’t change so often) to make a manual QA’s daily work easier. This is a great solution for recurring testing although the code still has to be maintained and adjusted along the way (which requires some coding knowledge).
When working on a test that involves a complicated business flow in the application, the recording might be useful for understanding how controls/elements should be interacted with.
Having said all that, there are many companies that are actively working on smart solutions for code-free test development utilizing Machine Learning and Artificial Intelligence. I’ll keep you posted… 🙂
How many times did you receive an automatic test report showing massive failures?
How many times have you banged your head against your desk going crazy, saying “why can’t this automatic test report ever be green“?
How many times did you hear managers saying that “the automatic tests must always be green” and “it’s just unacceptable that these tests always have a certain amount of failures“?
Let me just tell you now, when it comes to automated UI tests, it just doesn’t exist. It simply cannot exist. And if you ever see it, you are definitely, one hundred percent, doing something wrong. Seriously wrong. And let me tell you why…
UI automated tests are usually manual functional tests “gone-automatic”. This means that your automatic tests are bounded to a set of features, business flows, and UI structure within your application. Moreover, these tests, which are intended to “replace” human interaction (manual testers) are subjected to external factors such as network latency, UI rendering time, application (or lab) configurations, and many more…
Your state-of-the-art product is under constant development. Features are being added, removed, and changed continuously according to your organizational roadmap and customer demands and requirements. This means that the application under test (AUT) is constantly changing. And if the AUT is constantly changing so should the tests.
Developing a UI automated test is very much like developing a product. It has requirements (i.e., what features are to be tested, and how), it has a detailed design (or it should have), and it’s written in code and thus subjected to code writing conventions, design patterns, object model, clean code and other beautiful buzz-words. And very much like developing a product, or any other piece of software for that matter, it also has bugs. These bugs will usually manifest as false-negative results indicating a bug in the AUT while the actual reason for the test’s failure is the test itself (which should be fixed).
Generally, test failures can be divided into four (4) categories:
(1) Automation Bugs — an actual bug in the test scenario or infrastructure (2) Change in the AUT — an unexpected change in the AUT, like changing an id of a certain element without communicating the change to the automation team. In this situation, the automation test will look for an id that simply doesn’t exist anymore. (3) AUT Bugs — an actual bug that causes the test to fail (best case) (4) Settings & Configuration — test failures due to missing settings and/or configurations. For example, reaching the API calls per hour limit will cause all tests to fail.
While AUT Bugs are true-negatives all other failure types are considered false-negatives and indicate an unknown problem which may be a real problem, or not.
So what should we expect?
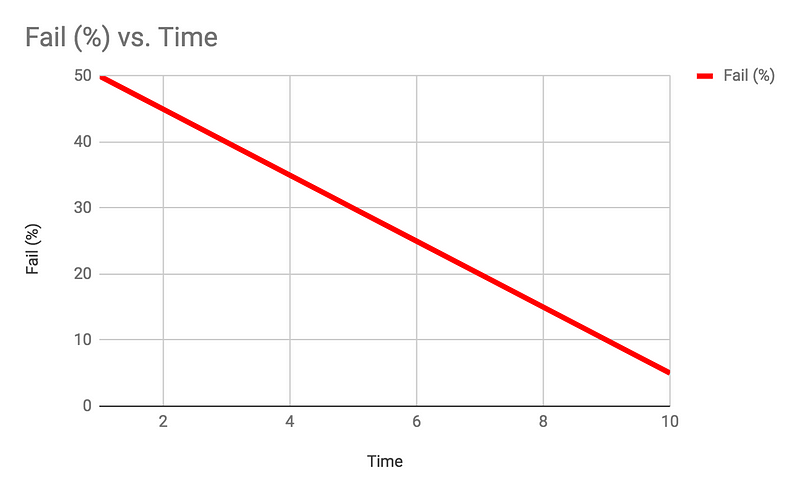
Let’s consider a product with a monthly release. During the first phase of the release, when new code is constantly added (new features, adjusted features, etc.), we should expect a rather big amount of failures in our automated tests due to the changes in the AUT.
As the release progresses, we should expect a decrease in the amount of failed tests as they are being adjusted or fixed, and application bugs (which cause the tests to fail — as they should) are being fixed. At the end of the release cycle, all test failures should reflect application bugs that are not intended to be fixed as part of that release.
This should be reflected in any release cycle, whether weekly, monthly, quarterly, or any other cycle time frame. Additionally, this applies to both SAAS and on-premise applications.
Its all about reporting…
So far we’ve established that an all-green report is a very rare breed that usually indicates that something is going wrong. But we’ve yet to discuss what should be done and how this whole mess can be sorted out.
The answer is manual classification. This means that we should manually investigate the reason for each failure and classify that failure to one of the four types mentioned above. By doing so we get a clear understanding of what is actually going on. When we report that we have 10% failures, it has no value nor meaning as we have no idea what are those failures. Performing the proposed manual curation over time will provide us with a good indication of what is going on in our tests, what should be improved, and where.
Developing automated UI tests is a must nowadays. Every development organization invests resources in automating their functional tests which mimic user interaction with their application.
There are several ways to develop UI tests, but I see them as two strategies: Recording and Developing. Some organizations prefer the “Recording” strategy in which the tester’s actions are recorded as code and can be executed automatically afterward. This approach is suitable when all tests are super-simple and require no validation nor code maintenance.
Personally, I don’t believe in this strategy as it cannot produce the required value for the organization. Although this strategy enables the creation of automatic tests without having to hire developers (can be done by manual QA testers), it lacks scale and cannot be used for complex tests.
The second strategy would be hiring developers to create an object-model and use it to develop and maintain automatic tests. If you ask me, this is the best way to go about automating functional tests (even though it might be more expensive in the short term). As the Application Under Test (AUT) is constantly evolving and changing, tests will have to change and be adjusted along the way. It is no secret that test automation requires constant maintenance (As does manual testing), and a well-written code is easier to maintain and requires less attention.
So, as you probably figured out by now, I will be talking about what I consider the main pitfalls and the best practices to avoid them when developing (not recording) automatic tests using the page-object model (POM).
Common Test Automation Frameworks
Keyword Driven Testing (KDT)
Keyword-Driven Testing (KDT), also referred to as “Table-Driven Testing”, utilizes keywords to specify the actual steps of the test-case. The keywords are usually actions performed on the AUT. The common usage of KDT is to arrange all actions in tables with rows specifying each action to be performed and all required data to perform it. Keywords can be divided into roughly two groups: High-level and Low-level keywords. High-level keywords represent business actions (i.e. Login) and Low-level keywords represent basic actions (i.e. click button, enter text).
Keyword (Action) KDT enables test-case design and development during while the AUT is still under development. This major advantage doesn’t cover test-case automation implementation as it requires the AUT (or the relevant AUT component) to be ready or at list usable to some extent.
State-Driven Testing (SDT)
State-Driven Testing (SDT) extends KDT and aims to improve it by referring to pages or windows as states of the AUT. SDT actions are not generic like low-level keywords (i.e. click button) but specific to the page or window (click login button). Each test object contains all methods required to interact with the page. For example, a user entry test object will contain the following methods: set_user_details (filling all required user details in the page), select_save (click the “save” button), select_cancel (click the “cancel” button).
The Page-Object Model
Test automation frameworks require an object model on which they can be applied. The most common automation object model today is the Page-Object Model (POM), which is sometimes referred to as the Page-Object Pattern. POM is usually used for testing web application but can be easily applied for desktop or mobile applications.
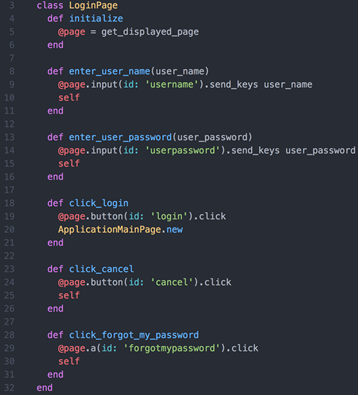
An example of a login page object high-level structure.
The main idea behind POM is to represent on-screen interaction and element manipulations inside objects which represent the actual displayed page or window. For example, a Login page object may contain the following methods: enter_user_name, enter_user_password, click_login, click_cancel, click_forgot_my_password. In other words, each page and its functionality should be represented by a page-object. Sometimes, menus and panels, which are presented across several pages will be represented in a separated page-object. The main benefits when using POM are:
Tests use classes rather than calling selectors directly
Selectors centralization. Reduce the probability to have duplicated selectors in different places in your code
An understandable and usable structure which enables readable and easy to develop tests
Page-object usage example
Possible Pitfalls When Using the Page-Object Model and How to Avoid Them
UI Test Automation implementation varies according to the SUT and the expected value to be gained. Even so, the basic concepts can be generally applied to any situation with relevant variations.
When implementing POM we are subjected to possible pitfalls that might result in unstable and unmaintainable tests. Here are some of the common miss-uses and how to try and avoid them.
1 — Over implementation
when using a certain object-model we often try to implement it as it is without taking the time to think how that object-model can meet our business requirements. In other words, we should always think how the chosen object-model serves our goal (and provides value) rather than trying to implement it as is. POM over-implementation often results in huge amounts of objects (classes) which quite quickly become impossible to maintain. This is a huge problem for a UI Testing function in the organization as it prevents results delivery and requires lots of resources for maintenance. In other words, it reduces the value received from the UI Automation function to almost nothing.
Proposed solution:
Create page-object classes which interact with the UI based on functionality and not based on visibility. The main goal is to represent the functionality of the UI and not the actual visual structure.
2 — Forgetting About the Code
UI Automation development is often subjected to very short timelines with clear results requirements, which may result in a quick-and-dirty code. If you ask me, there is nothing wrong with a quick-and-dirty solution as long as you add a refactoring task to your technical-debt backlog. However, we usually forget about our technical-debt and just leave the code as is. This may result in a “voodoo” (inconsistent) behavior and an impossible maintenance.
Proposed solution:
Developing UI test automation code is no different than product software code and should be treated as such. Thus, when writing test automation code, we should use common design patterns and principles. Additionally, we should pay extra attention to technical-debts and strive for clean and readable code.
3 — Mixing basic actions in test objects
When creating test objects it is usually tempting to use the basic abilities of the technical framework (Selenium, CodedUI etc) to perform basic actions for clicking an element, reading text from an element, sending text to an element and such. This approach has an inherited flaw in it as these actions almost always require validations and additional actions. For example, before sending text to an element we usually want to scroll to it so it will be visible on screen (something a user would probably do). Additionally, we would like to make sure that the sent text was indeed sent to the element as expected.
Proposed solution:
create an “external” object (could be a singular instance) in which you will implement all basic actions and capabilities such as click_element, send_text, read_text, scroll_to_element etc. The main idea behind this solution is to have all actions etc.in one place. This way we gain more reliable and resilient actions with easy maintenance.
Proposed implementation for Basic Actions
4 — Not Enough Validations
A UI Test scenario should mimic a user interaction with the SUT. Such interaction involves navigating between different pages (windows) of the SUT and using different functionalities. Many times, tests provide false-positive results when a navigation or action did not go as planned but did not raise any error in the test or SUT.
For example, entering text into an element but the text was not sent to the element for some reason. In this case, the test is not successful but might still pass. What if we need this value for other tests? What if this value is needed for an underlying process in the SUT? Is this OK that our test missed that?
Proposed solution:
Validate each actionable step. Every action such as button_click, enter_text etc should always be provided with the validation criteria for the action’s outcome. Or in other words, every action should have an expected result. This way we eliminate the risk that a certain action will not work as expected without our tests detecting it.
5 — Testing the wrong system…
Developing tests (manual or automated) for an application you don’t know and understand is bad. Be familiar with the application you are testing, understand the business flows and the business behind the application.
Proposed solution:
The name of the game is “business flow”. Invest in learning the application, its core components and the business behind them. Understand the way customers use the application and identify the critical business flows that should be covered first. Remember, understanding the AUT is the best way to develop valuable tests.
6 — Mapping instead of testing
Many times, we put too much effort into modeling and representing the AUT rather than actually testing it. In other words, we put too much effort into creating objects which display functionalities that we do not test or have no tests for them. This usually results in detailed and well-modeled useless objects as they are not included in any test case.
Proposed solution:
If there is no test scenario for a certain feature or component there is no need to implement it. Make sure to implement those objects which provides value and actively participate in tests. And what about those features and components that you didn’t implement? Don’t worry, you’ll get to them when you’ll have a test-case which require them. To make a long story short: No scenario, No implementation.